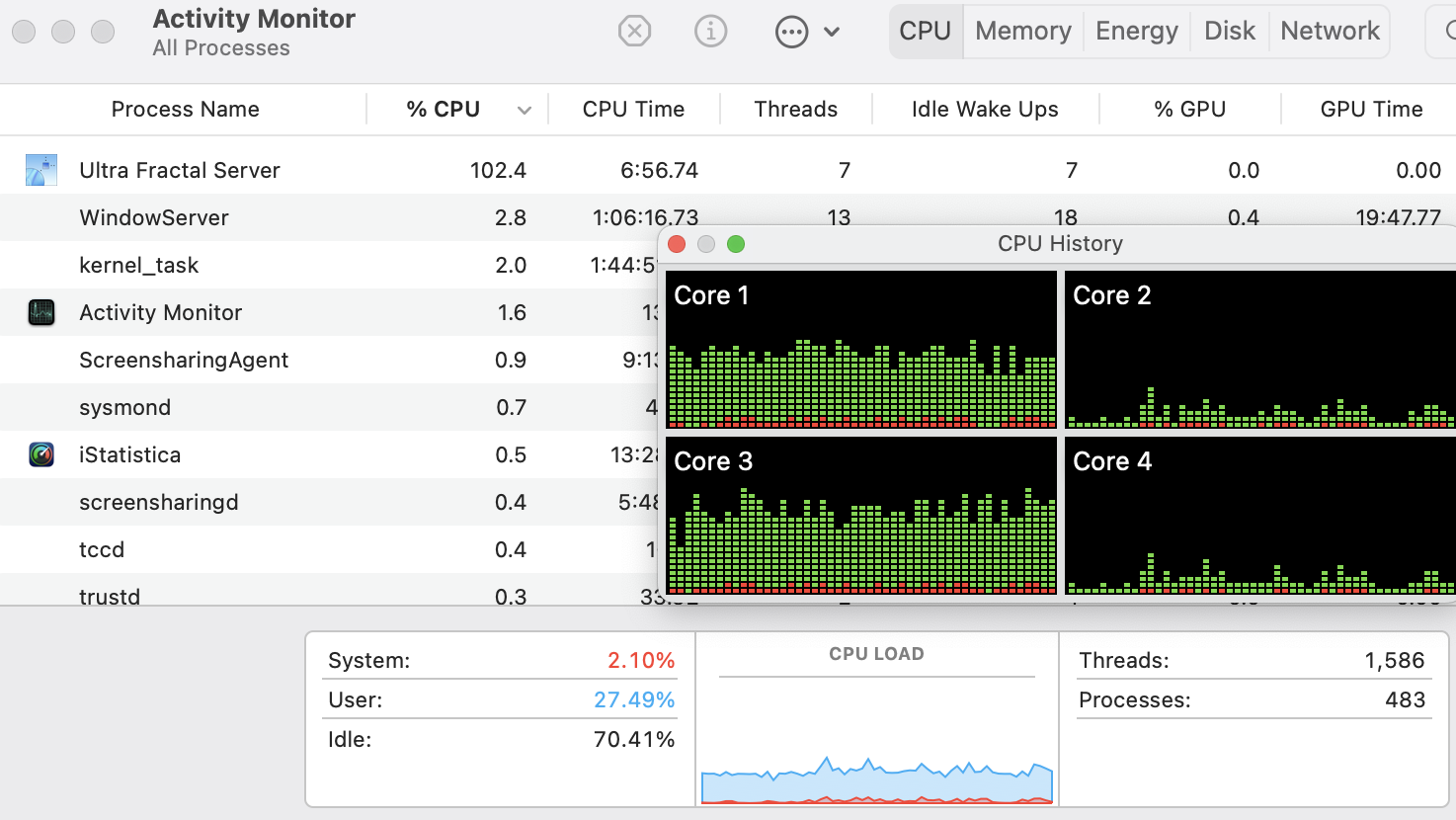
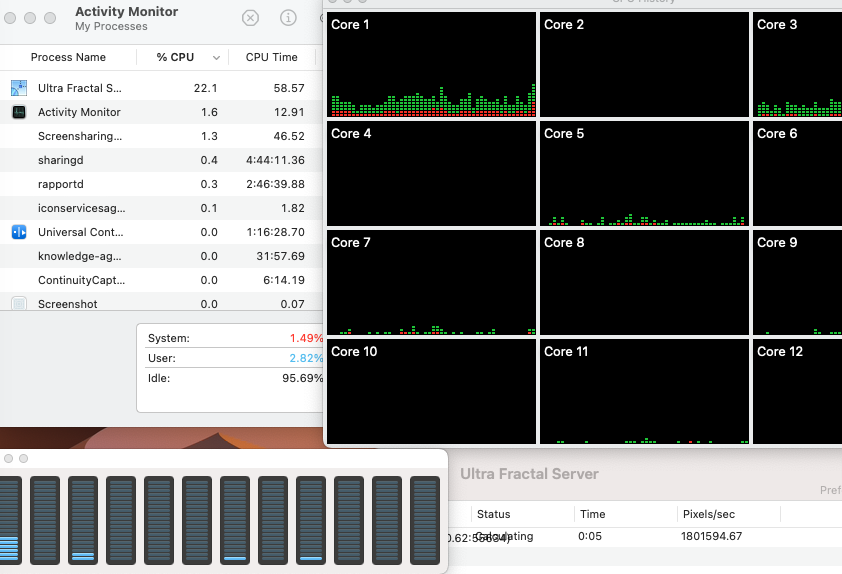
I've tried both with the client on my TR Pro and the server on the 10/20 core i7-6950x and the other way around; regardless of which direction it's going, only one core on the machine set up as the server is used. (tested that just in case it was deciding offload wasn't worthwhile). I checked affinity and it was set to all cores for the server process and the client was set to 20 cores on the 6950x in case that matters. Multiple processes of the server can't be started but multiple connections from the same source can be made so I tried that; all of them ran on the same core and it just slowed things down.
Also tried the various rendering methods, turning off anti-aliasing, etc. Looking at the iterations count in the server monitor, it seemed to display a large jump every so often, like it would occasionally run on all cores and switch back. No CPU use by anything but Windows processes on either when I tested so the low priority default shouldn't have mattered (and shouldn't affect threading anyway).
The old machine is around 1/3 as fast as the new so another 30% speed is pretty good considering the time larger images or animation can take. Network connection is through an unmanaged switch + the base router and I'm getting 120MB/s between machines on SMB and under 1ms pings so I doubt that's an issue.
Any settings I might be missing or other things I should try or is this a bug?